
主题
nodejs项目中使用graphQL
前言
上一篇文章介绍了graphql类型、前后端交互如何传参、增删改查、调试等,点击跳转上一篇:《graphQL实践》 在前端使用graphql很简单,上一篇中有使用说明,但是上一篇中在nodejs中用graphql都是在一个js文件内书写schema和resolver的,这在开发项目时候显然不合理,那么这一片文章就来继续完善, 如何将代码拆分为不同的模块,以及在express、Koa、Egg内的使用
使用核心的插件是官方提供的graphql-tools:graphql-tools官方文档
注意:graphql-tools这个包已经被弃用,现在它只导出makeExecutableSchema,它以停止更新,请使用@graphql tools/schema、@graphql tools/utils等
下载
bash
npm i graphql express-graphql @graphql-tools/schema @graphql-tools/merge @graphql-tools/load-files --save
## 使用的版本
"express-graphql": "^0.12.0"
"@graphql-tools/load-files": "^6.5.3"
"@graphql-tools/merge": "^8.2.1"
"@graphql-tools/schema": "^8.3.1"该插件提供了一些方法,例如:
1、
makeExecutableSchema:可以将typeDefs和resolvers揉在一起,一起传给graphqlHTTP,makeExecutableSchema方法接收一个对象,对象内只有typeDefs选项是必需的。
js
const { makeExecutableSchema } from '@graphql-tools/schema'
const schema = makeExecutableSchema({
typeDefs,
resolvers, // optional
logger, // optional
resolverValidationOptions: {}, // optional
parseOptions: {}, // optional
inheritResolversFromInterfaces: false // optional
})
app.use("/graphql",graphqlHTTP({
schema,
graphiql: true
})
);2、
@graphql-tools/merge:插件中有两个方法mergeTypeDefs和mergeResolvers,分别用来合并各个文件按中的typeDefs和resovers.@graphql-tools/load-files:插件中有一个loadFilesSync方法,用于加载文件 更多查看官网模式合并
js
const { mergeTypeDefs, mergeResolvers } = require("@graphql-tools/merge");
// 加载并合并typeDefs文件
const typeDefs = mergeTypeDefs(loadFilesSync(path.join(__dirname, "/**/*.graphql")));
// 加载并合并resolvers
const resolvers = mergeResolvers(loadFilesSync(path.join(__dirname, "/**/*.resolvers.js")/*,{ignoreIndex:true}*/));注意:
- ① 默认情况下,
loadFilesSync函数不会忽略名为index.jsor的文件index.ts,但您可以将ignoreIndex选项设置true为启用此行为。但是我这里用的是自动加载.resolvers.js结尾的文件,不是某个文件夹下的所有js文件,所以不需要添加此配置项。 - ②
mergeResolvers只是将普通的 JavaScript 对象合并在一起。这意味着您应该小心有命名冲突的查询、突变或订阅。
一. Express + graphql + mysql案例
1、环境搭建
bash
mkdir express-graphql-demo && cd express-graphql-demo
npm init -y
npm i --save express express-graphql @graphql-tools/schema @graphql-tools/merge @graphql-tools/load-files sequelize mysql2根目录新建入口文件 index.js
js
const express = require("express");
const app = express();
app.use("/graphql", (req, res) => {
res.send("ok");
});
app.listen(3000, () => {
console.log("serve runing at port 3000");
});启动服务成功 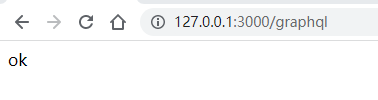
2、接入graphql
现在改造/index.js,加入graphql (1)引入graphqlHTTP中间件,并挂载,用于接收所有graphql请求,建议路由名字命名为/graphql,一般情况下,这一个路由就能处理整个项目的graphql请求,且请求方式只能为post.若还需要restful接口另说。
js
const { graphqlHTTP } = require("express-graphql");修改/graphql路由
js
app.use("/graphql",graphqlHTTP({
schema,
graphiql: true
})
);说明: 这里graphqlHTTP中间件应该是有三个参数,分别为schema、rootValue``、graphiql,(模式,解析器,是否开启调试面板),但是我这里仅仅写了一个参数,因为我打算将schema和resolvers拆分到各自的功能模块文件夹下面,再利用makeExecutableSchema 将二者结合到一起,传递给graphqlHTTP,所以这里看到的一个参数schema`其实已经包含二者。
3、拆分graphql模块
根目录新建文件夹graphql,内部分别建二级目录user,新建文件/graphql/schema.js,内容如下:
js
// /graphql/schema.js文件
const { makeExecutableSchema } = require("@graphql-tools/schema");
const { mergeTypeDefs, mergeResolvers } = require("@graphql-tools/merge");
const { loadFilesSync } = require("@graphql-tools/load-files");
const path = require("path");
// 加载并合并typeDefs文件
const typeDefs = mergeTypeDefs(loadFilesSync(path.join(__dirname, "/**/*.graphql")));
// 加载并合并resolvers
const resolvers = mergeResolvers(loadFilesSync(path.join(__dirname, "/**/*.resolvers.js")/* ,{ignoreIndex:true} */));
module.exports = makeExecutableSchema({ typeDefs, resolvers });说明: path.join(__dirname, "/**/*.graphql")表示/graphql目录下面的所有二级目录下面的所有以.graphql结尾的文件, path.join(__dirname, "/**/*.resolvers.js")表示/graphql目录下面的所有二级目录下面的所有以.resolvers.js结尾的文件,由于这里使用了自动加载resolvers,所以对应模块下面的resolvers文件命名最好遵循官方规定,以.resolvers.js结尾。当然也可以为其他,只要能找到
接着,再user目录下面新建user.graphql文件和user.resolvers.js文件
xxx.graphql文件用于定义type,所有和用户相关的schema Type都定义再里面 xxx.resolvers.js 文件用于定义每个Query和每个Mutation里面对应的处理函数,
例如: 
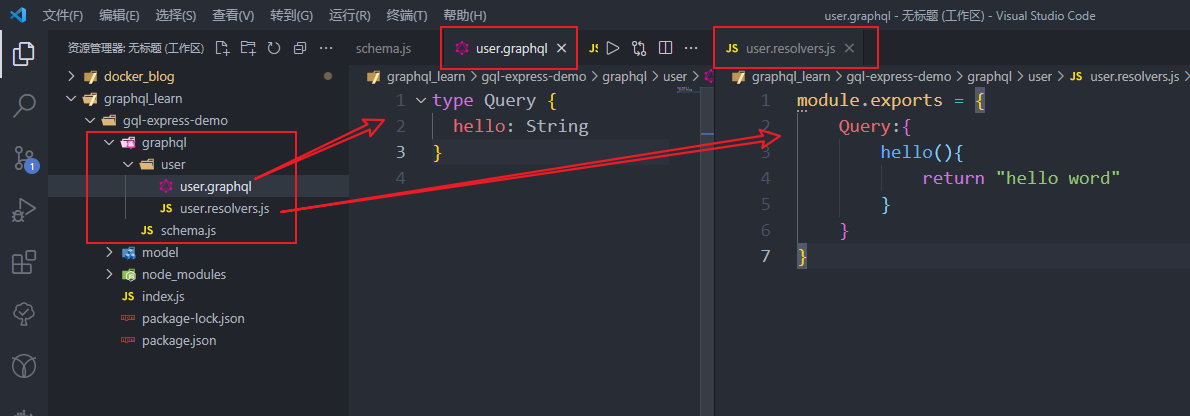
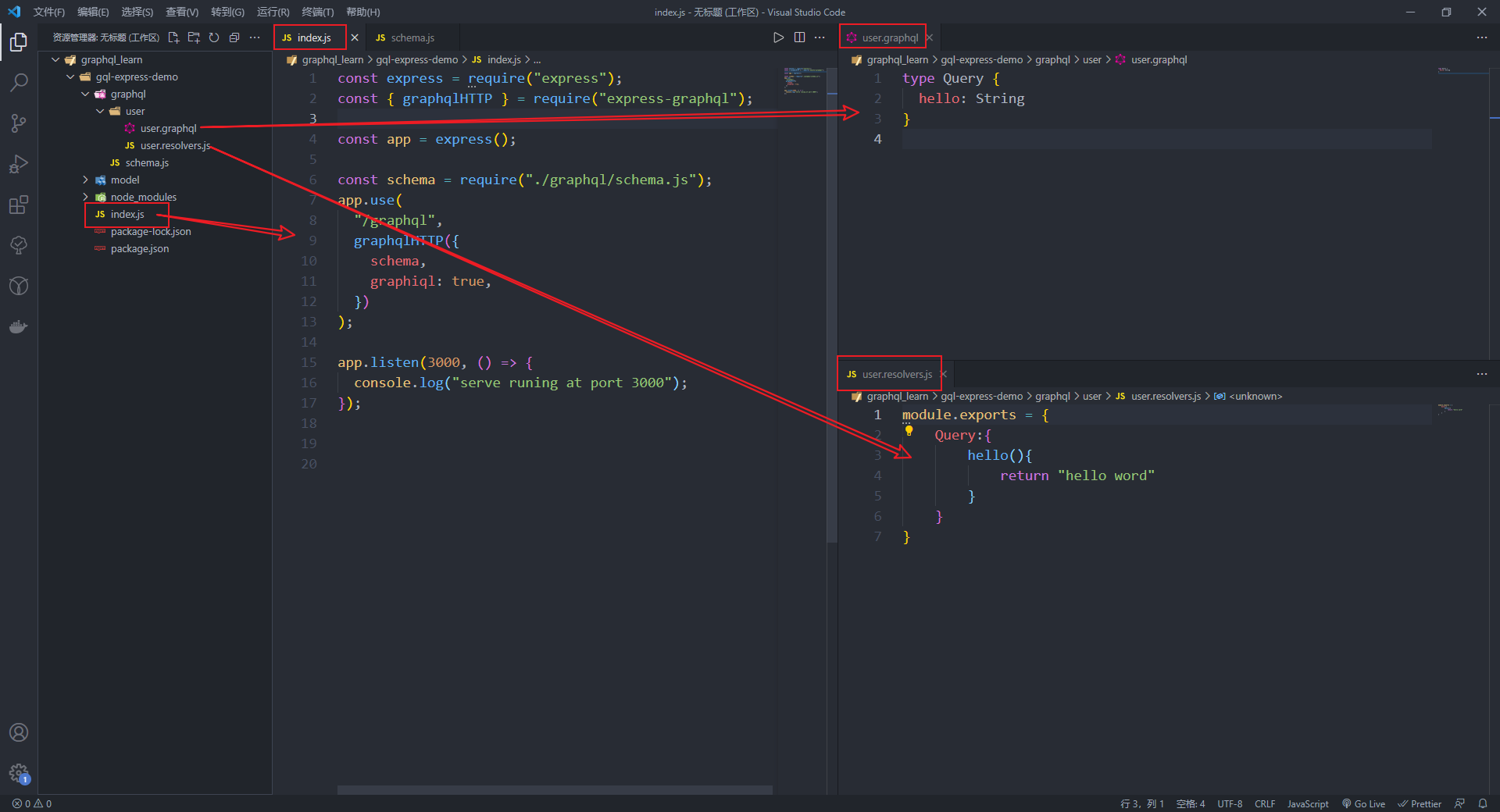
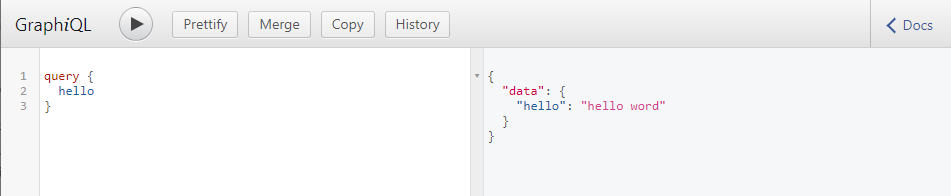
对于xxx.graphql文件,可以安装vscode插件,让代码高亮,且有提示
4、接入数据库(sequelize)
根目录新建目录model,里面创建文件db.js,用作连接数据库的配置文件,内容如下:
先保证数据库存在,若不存在,得手动创建数据库
js
// /model/db.js
const { Sequelize } = require("sequelize");
// 创建实例对象并连接数据库
// gql_prod为数据库名称, ljh为用户名,123456为密码
const db = new Sequelize('gql_prod','ljh','123456',{
dialect:'mysql', // 数据库类型,支持: 'mysql', 'sqlite', 'postgres', 'mssql'
host:'180.76.177.217', // 自定义连接地址,可以是ip或者域名,默认为本机:localhost
port:'3306', // 端口号,默认为3306
logging:true, // 是否开启日志(建议开启,有利于我们查看进行的操作)
pool:{ // 连接池
min:0,
max:5,
idle:30000, //空闲最长连接时间
acquire:60000, //建立连接最长时间
},
define: { // 统一定义表内的一些属性
timestamps: false, // 取消默认字段 createAt, updateAt
freezeTableName: true, // 允许给表设置别名
underscored: false // 字段以下划线(_)来分割(默认是驼峰命名风格)
},
dialectOptions: {
dateStrings: true, // 正确显示时间 否则查出来的时间格式为 2019-08-27T12:02:05.000Z
typeCast: true
},
timezone: "+08:00" // 改为标准时区
})
module.exports = db;接着再在/index.js文件内测试数据库是否能正常连接
js
const sequelize = require('./model/db')
async function tectConnectDB() {
try {
// 用于测试数据库链接情况
await sequelize.authenticate();
console.log("数据库链接成功");
} catch (error) {
console.error("数据库链接错误: ", error);
}
}
tectConnectDB();然后启动项目

5、创建user数据库模型,同步模型
在model文件夹下创建user.js,作为用户的数据库模型文件
js
// /model/user.js
const { Sequelize, DataTypes } = require("sequelize");
const sequelize = require("./db");
const MD5 = require("../utils/MD5");
const User = sequelize.define(
"user",
{
// 在这里定义模型属性(字段)
id: {
type: DataTypes.UUID, // 数据类型
primaryKey: true, // 主键
allowNull: false, // k允许为空 设置列的 allowNull为 false 将会为该列增加 非空 属性
unique: true, // unique: 'compositeIndex', unique: true
defaultValue: Sequelize.UUIDV4
},
// 在模型中的名字是小驼峰,在表中的列名可以用 field 属性来指定
userName: {
type: Sequelize.STRING
},
// 创建外码
passWord: {
type: Sequelize.STRING,
set(value) {
// 设置存入数据库的值格式化,(密码加密)
this.setDataValue("passWord", MD5(value));
}
},
nickName: {
type: DataTypes.STRING
},
sex: {
type: DataTypes.INTEGER
}
},
{
// 这是其他模型参数
freezeTableName: true, // 冻结表名 user 不会变成复数 users
timetamps: true, // 自定添加创建时间修改时间字段createdAt 和 updatedAt
underscored: false, // 防止驼峰式字段被默认转为下划线 userId不会变成user_id
createdAt: false, //不想要 createdAt
updatedAt: "updateTimestamp" // 想要 updatedAt 但是希望名称叫做 updateTimestamp
}
);
// 同步模型
User.sync();
// 定义表之间的关联
// User.associate = function () {};
module.exports = User;接着修改user.graphql文件,定义查询用户信息和用户注册接口人入参和出参类型,再在对应的user.resolvers.js文件定义相关的用户查询和用户注册处理函数
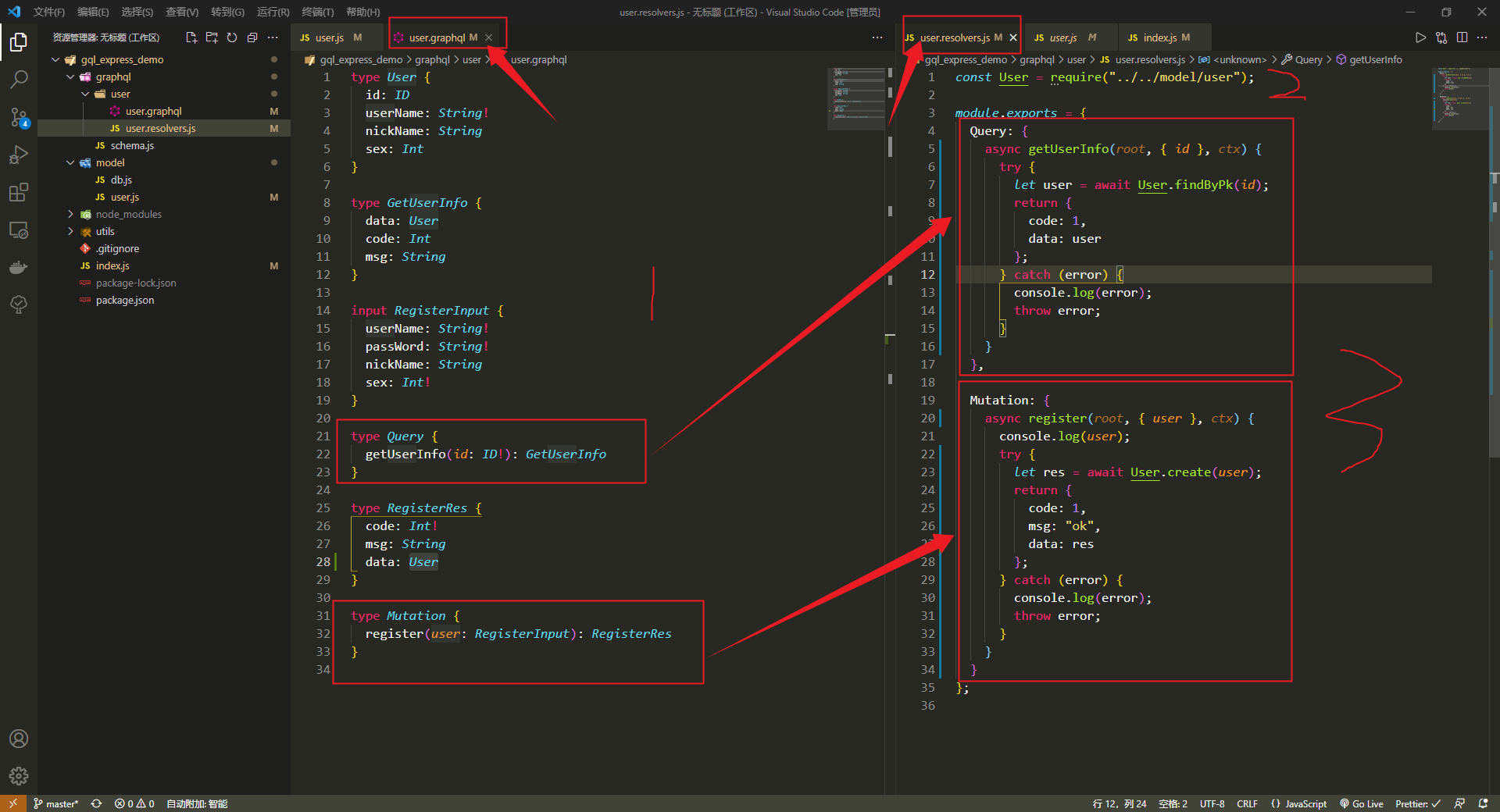 user.graphql文件
user.graphql文件
graphql
type User {
id: ID
userName: String!
nickName: String
sex: Int
}
type GetUserInfo {
data: User
code: Int
msg: String
}
input RegisterInput {
userName: String!
passWord: String!
nickName: String
sex: Int!
}
type Query {
getUserInfo(id: ID!): GetUserInfo
}
type RegisterRes {
code: Int!
msg: String
data: User
}
type Mutation {
register(user: RegisterInput): RegisterRes
}user.resolvers.js文件
js
const User = require("../../model/user");
module.exports = {
Query: {
async getUserInfo(root, { id }, ctx) {
try {
let user = await User.findByPk(id);
return {
code: 1,
data: user
};
} catch (error) {
console.log(error);
throw error;
}
}
},
Mutation: {
async register(root, { user }, ctx) {
console.log(user);
try {
let res = await User.create(user);
return {
code: 1,
msg: "ok",
data: res
};
} catch (error) {
console.log(error);
throw error;
}
}
}
};6、测试接口
用户注册
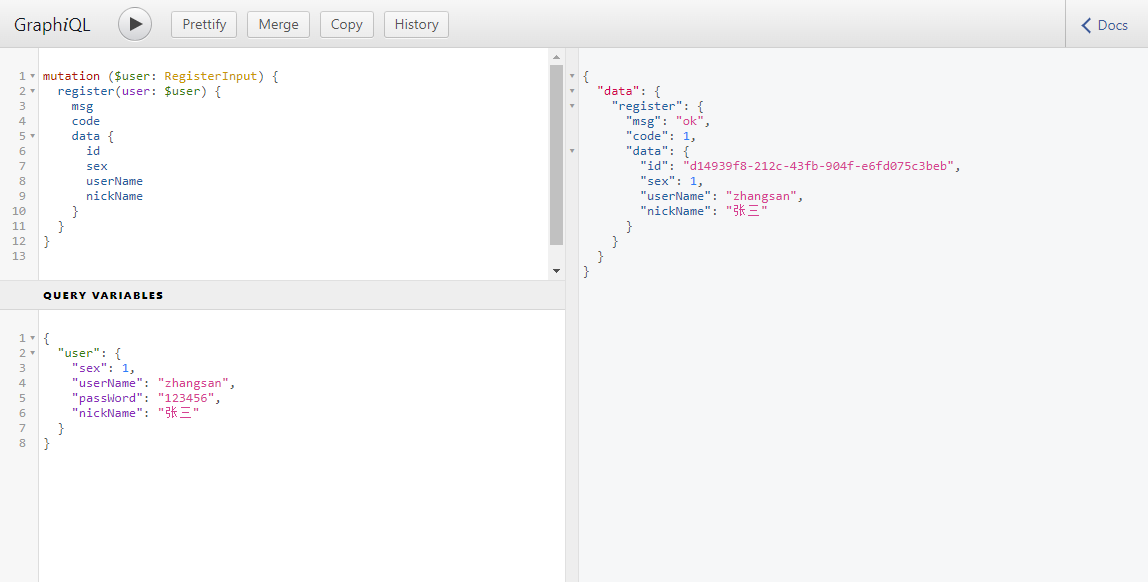
数据库

查询用户

7、完整demo
二. Egg + graphql使用
在egg项目中使用graphql,主要用到插件egg-graphql,npm地址:https://www.npmjs.com/package/egg-graphql
1、环境搭建
(1)初始化项目,安装依赖
bash
mkdir gql_egg_demo && cd gql_egg_demo
npm init egg --type=simple
npm install
i egg-graphql --save
npm run devnpm run dev启动项目,访问http://127.0.0.1:7001
2、引入egg-graphql,并配置
上一步已经下载了插件egg-graphql,这里只需要引入: (1)开启插件
js
// config/plugin.js
graphql: {
enable: true,
package: "egg-graphql"
}(2)在 config/config.${env}.js 配置提供 graphql 的路由。
js
// config/config.${env}.js
config.graphql = {
router: "/graphql",
// 是否加载到 app 上,默认开启
app: true,
// 是否加载到 agent 上,默认关闭
agent: false,
// 是否加载开发者工具 graphiql, 默认开启。路由同 router 字段。使用浏览器打开该可见。
graphiql: true,
//是否设置默认的Query和Mutation, 默认关闭
defaultEmptySchema: false,
// graphQL 路由前的拦截器
onPreGraphQL: function*(ctx) {},
// 开发工具 graphiQL 路由前的拦截器,建议用于做权限操作(如只提供开发者使用)
onPreGraphiQL: function*(ctx) {}
};
// 添加中间件拦截请求
config.middleware = ["graphql"];注意:官方这里用了ApolloServer,一个第三方的库,封装了一些东西,功能更强大,我这里暂时不用,有关Apollo,会专门有一篇文章讲解其使用方法
3、建graphql相关目录和文件,编写代码
app目录下新建graphql目录,graphql 相关逻辑放到 app/graphql 下。 graphql目录结构如下:
.
├── app
│ ├── graphql
│ │ ├── project
│ │ │ └── schema.graphql
│ │ └── user // 一个graphql模型
│ │ ├── connector.js
│ │ ├── resolver.js
│ │ └── schema.graphql
│ ├── model
│ │ └── user.js
│ ├── public
│ └── router.jsgraphql下面的每个模块都包必须包含三个文件:schema.graphql、resolver.js、connector.js,具体介绍如下:
请求走的流程大概为:schema.graphql --> resolver.js --> connector.js --> 数据源(后端接口,数据库,service等)
就用一个用户模块 user 来举例
(1)编写schema.graphql(schema.graphql) GraphQL 使用 Schema 来描述数据。 这个 schema 表明了一个数据模型中,有哪些字段,GraphQL 类库的其他部分会来消费这个 Schema 对象。
ts
## /app/graphql/user/schema.graphql文件
type User {
id: ID
name: String
age: Int
hobby: [String]
}
type Query {
getUser: User
}(2)编写connector(connector.js) 编写完 schema 之后,graphql 知道有哪些数据了,但他还需要知道“如何去取”, connector 的角色就在于此。 connector 的职责就是“取数”, 他既可以调用 rpc 接口取数,又可以调用内置的 orm 插件去取数,还可以直接调用 egg 的 service。
注:这里我暂时先写死数据,后面再详细讲解connector到不同的数据源取数据的示例
js
// /app/graphql/user/connector.js
"use strict";
class UserConnector {
constructor(ctx) {
this.ctx = ctx;
}
getUser(user) {
return {
id: "123456",
name: "zhangsan",
age: 13,
hobby: ["吃饭", "睡觉", "敲代码"]
};
}
}
module.exports = UserConnector;(3)编写resolver(resolver.js) 我们编写好取数逻辑后,就要对用户的查询进行处理了,这个处理代码称之为 resolver.
其实 resolver 非常简单,就是针对你暴露的查询接口,调用相应的connector去取数即可,如下:
js
"use strict";
module.exports = {
Query: {
async getUser(root, { id }, ctx) {
return await ctx.connector.user.getUser();
}
}
};4、尝试请求
当完成上面3个步骤后,启动项目,打开浏览器http://127.0.0.1:7001/graphql,会发现还没请求呢,就出现一个错误提示:invalid csrf token, 
这是由于,egg框架内置了 CSRF 防范方案(跨站请求伪造),当发送POST、PUT、PATCH、DELETE 等请求时候,会对请求进行校验,具体查看Egg官网“安全威胁 CSRF 的防范”
这里为了方便,开发环境下,可以关闭csrf,开启与关闭配置
/config目录下新建config.local.js文件,内容如下(本地开发环境配置)
js
// /config/config.local.js
module.exports = appInfo => {
const config = (exports = {});
config.security = {
csrf: {
enable: false // 关闭csrf
}
};
return {
...config
};
};重新请求
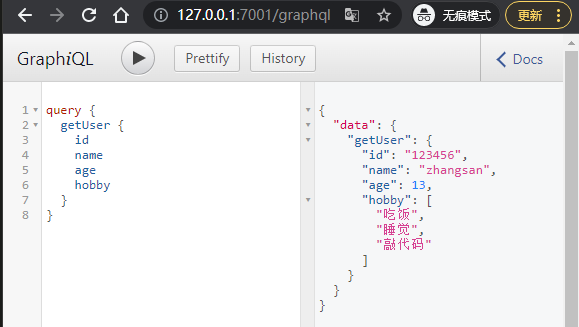
5、抽离type Query和type Mutation
项目中只能定义一个query和mutation,多了就会报错
每个模块下面的schema.graphql文件用于存放这个模块下的一些类型
在graphql目录下新建query/schema.graphql和mutation/schema.graphql,分别放type Query和type Mutation,当然也可以建一个公共文件夹,所有的type Query和所有的type Mutation都放到一个schema.graphql文件中 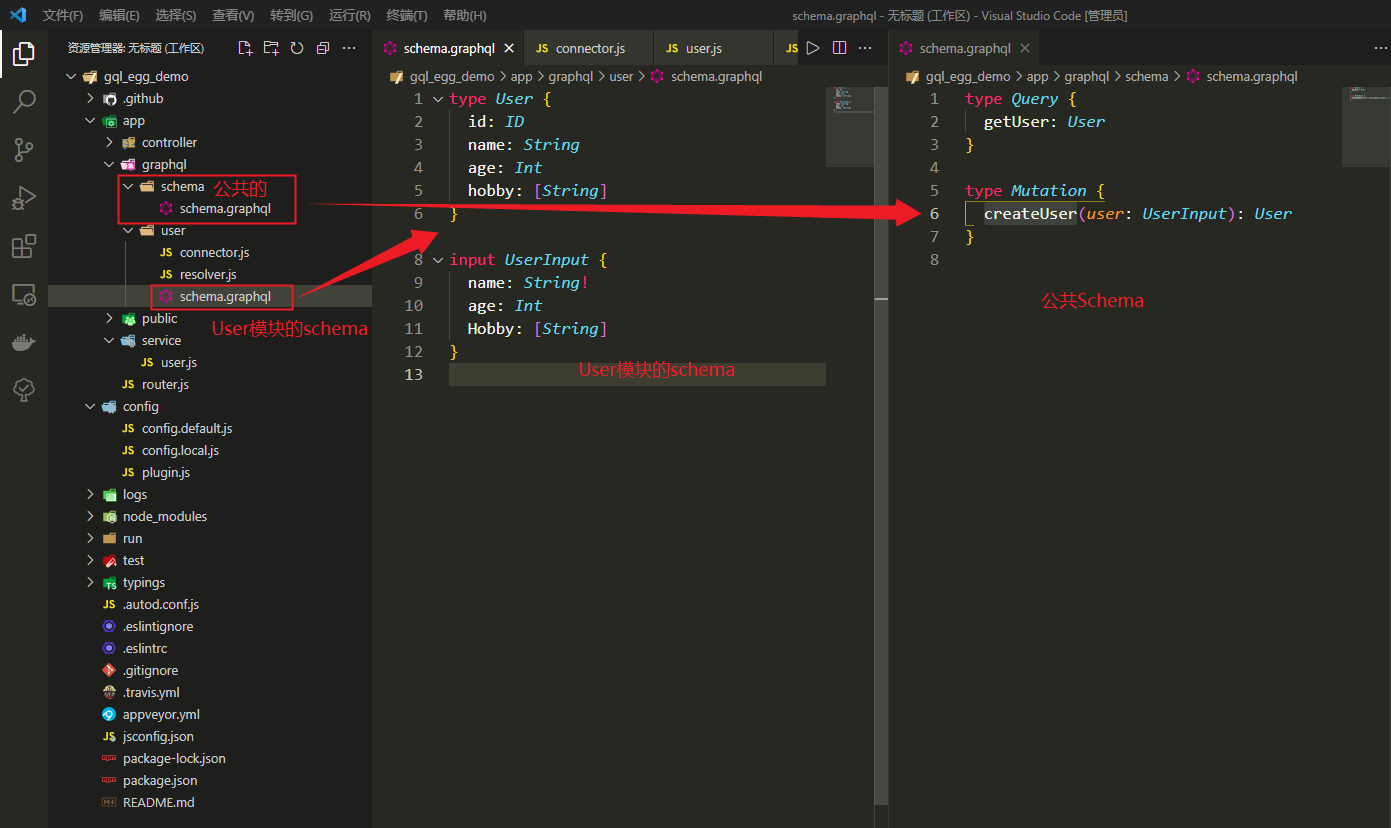
6、connector的不同数据源
请求走的流程大概为:
schema.graphql-->resolver.js-->connector.js-->数据源(后端接口,数据库,service等)
上面第三点说到,connector 的职责就是“取数”,可以理解为,它是graphql请求提供数据源的入口点
当请求到了connector,可以根据不同情况和业务需求,提供给graphql不同的数据分别为 后端接口,数据库,service等
6.1 后端接口作为数据源
在很多的应用中,都会用nodejs作为BBF层(也就是常说的中间层),整合不同后端服务接口,再由node中间层提供给web应用http接口,这里,node中间层起到的作用有一部分就是接口转发,后端提供的接口可能是http接口, 也能是Dubbo,或者是其他接口,但是对于node中间层来说,后端接口都是中间层的一个数据源,在实际业务中,会更具具体的需求来做。这里便以后端提供http接口为例来做示例
当后端提供的http接口时,egg中可以通过curl来发送请求(HttpClient),当然,也可以通过其他工具,例如axios等。
下面是一个简单的示例
js
// connector.js
class TestConnector {
constructor(ctx) {
this.ctx = ctx;
}
async getBaiduHtml() {
let result = await this.ctx.curl("http://www.baidu.com", {
timeout: 3000
});
// console.log(result);
return result.data.toString();
}
}
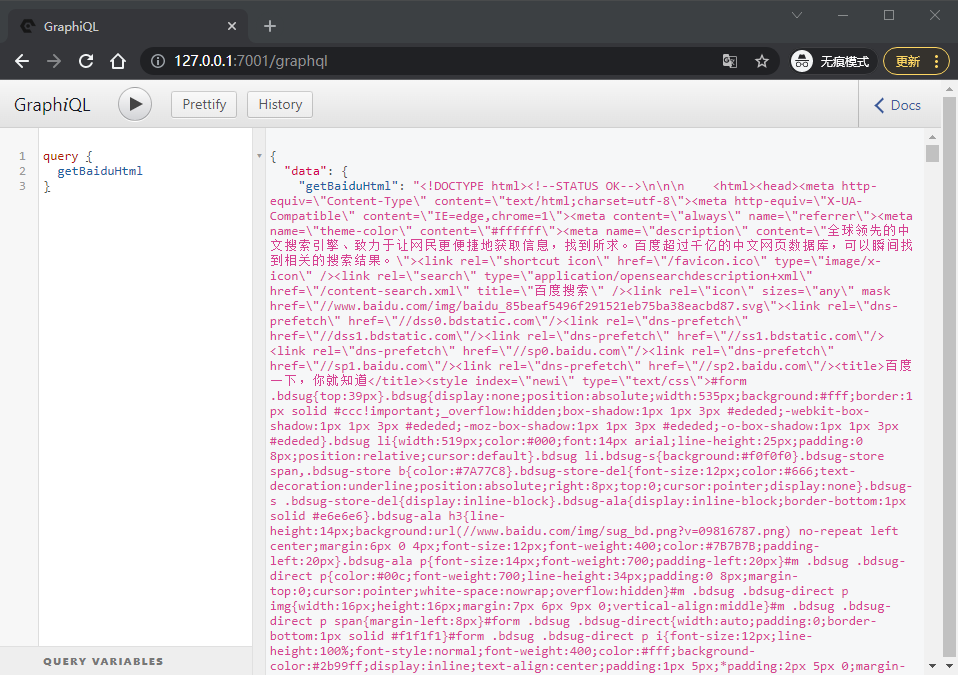
module.exports = TestConnector;效果

6.2 connector.js直接调用service
在egg中,约定的service内是处理服务的,也就是说,不管是数据库查询还是接口转发,逻辑都可以写到service中,统一管理,然后再由controller,根据需要来调取不同的service,得到对应的数据,对于graphql,egg的controller好像显得没什么用处了,确实,graphql内,通过connector可以充当controller的作用,在connector.js中调用egg内的service的示例如下:
js
// connector.js
'use strict';
class ArticleConnector {
constructor(ctx) {
this.ctx = ctx;
}
async getArticleInfoByService(iArticleID) {
return await this.ctx.service.article.getArticleByID(iArticleID);
}
}
module.exports = ArticleConnector;6.3 connector中操作数据库(dataloader)
7、一些注意事项
(1)项目中只能定义一个type Query 和一个type Mountent,多了会报错 (2)在基础配置是否设置默认的Query和Mutation, 需要设置为关闭(默认也是关闭,否则无法显式的设置query和mutation) (3)安装vscode插件对代码进行颜色高亮
(4)query和 mutation 中的方法和 我们的自定义类型,尽量添加文件名作为业务模块名_作为前缀,以防名字冲突而报错,例如:
graphql
type User_UserInfo {}
type Query {
User_getUserInfo:User_UserInfo
}(5)一定要将resolver.js内用到的类型在schema.graphql中声明完整,否则会报错
8、restful风格路径转发到graphql
有时候有这样的需求,有些接口为了方便前端查看,需要在/graphql路由的基础上加上二级路由,这时候,egg这边需要做一层路由重定向 因为项目的graphql路由是在config.{env}.js配置文件中配置的,这里为/graphql,router.js文件内不需要有这个路由,所以,当路由不为/graphql时候,就得人为重定向到/graphql才能取到数据。
我这里做了一个路由转发,如下:
js
// restful 路由
router.post("/graphql/:path",controller.redirectToGraphql.redirectToGraphql)
// 核心controller逻辑
async redirect2Graphql() {
let body = this.ctx.request.body;
let headers = this.ctx.request.headers;
const ctx = this.ctx;
let option = {
// 必须指定 method
method: 'POST',
// 通过 contentType 告诉 HttpClient 以 JSON 格式发送
contentType: 'json',
data: body,
headers: headers,
// 明确告诉 HttpClient 以 JSON 格式处理返回的响应 body
dataType: 'json'
};
// 如果是导出请求
if (this.ctx.request.path.includes('export')) {
delete option.dataType;
}
const result = await ctx.curl('http://127.0.0.1:7001' + this.app.config.BASE_URL + '/graphql', option);
ctx.status = 200;
ctx.set(result.headers); //将响应头信息写入到响应对象中,否则导出响应会失败
if (this.ctx.request.path.includes('export')) {
ctx.res.end(result.data);
}
else ctx.body = result.data;
}