
主题
Redis的使用
1、redis基础?
转载与:https://www.cnblogs.com/powertoolsteam/p/redis.html,若侵权请联系删除 在Web应用发展的初期,那时关系型数据库受到了较为广泛的关注和应用,原因是因为那时候Web站点基本上访问和并发不高、交互也较少。而在后来,随着访问量的提升,使用关系型数据库的Web站点多多少少都开始在性能上出现了一些瓶颈,而瓶颈的源头一般是在磁盘的I/O上。而随着互联网技术的进一步发展,各种类型的应用层出不穷,这导致在当今云计算、大数据盛行的时代,对性能有了更多的需求,主要体现在以下四个方面:
- 低延迟的读写速度:应用快速地反应能极大地提升用户的满意度
- 支撑海量的数据和流量:对于搜索这样大型应用而言,需要利用PB级别的数据和能应对百万级的流量
- 大规模集群的管理:系统管理员希望分布式应用能更简单的部署和管理
- 庞大运营成本的考量:IT部门希望在硬件成本、软件成本和人力成本能够有大幅度地降低
为了克服这一问题,NoSQL应运而生,它同时具备了高性能、可扩展性强、高可用等优点,受到广泛开发人员和仓库管理人员的青睐。
1.1、redis是什么
Redis是现在最受欢迎的NoSQL数据库之一,Redis是一个使用ANSI C编写的开源、包含多种数据结构、支持网络、基于内存、可选持久性的键值对存储数据库,
1.2、redis特性
- 1、基于内存运行,性能高效
- 2、支持分布式,理论上可以无限扩展
- 3、key-value存储系统
- 4、开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API
相比于其他数据库类型,Redis具备的特点是:
- C/S通讯模型
- 单进程单线程模型
- 丰富的数据类型
- 操作具有原子性
- 持久化
- 高并发读写
- 支持lua脚本
1.3、Redis的应用场景有哪些?
Redis 的应用场景包括:
- 缓存系统(“热点”数据:高频读、低频写)
- 计数器、
- 消息队列系统、
- 排行榜、
- 社交网络和实时系统

1.4、Redis的数据类型及主要特性
Redis提供的数据类型主要分为5种自有类型和一种自定义类型,这5种自有类型包括:String类型、哈希类型、列表类型、集合类型和顺序集合类型。 
1.4.1、String类型
它是一个二进制安全的字符串,意味着它不仅能够存储字符串、还能存储图片、视频等多种类型, 最大长度支持512M。
对每种数据类型,Redis都提供了丰富的操作命令,如:
- GET/MGET
- SET/SETEX/MSET/MSETNX
- INCR/DECR
- GETSET
- DEL
1.4.2、哈希类型(hash)
该类型是由field和关联的value组成的map。其中,field和value都是字符串类型的。
Hash的操作命令如下:
- GET/HMGET/HGETALL
- SET/HMSET/HSETNX
- EXISTS/HLEN
- KEYS/HDEL
- HVALS
1.4.3、列表类型(list)
该类型是一个插入顺序排序的字符串元素集合, 基于双链表实现。
List的操作命令如下:
- LPUSH/LPUSHX/LPOP/RPUSH/RPUSHX/RPOP/LINSERT/LSET
- LINDEX/LRANGE
- LLEN/LTRIM
1.4.4、集合类型(set)
Set类型是一种无顺序集合, 它和List类型最大的区别是:集合中的元素没有顺序, 且元素是唯一的。
Set类型的底层是通过哈希表实现的,其操作命令为:
- SADD/SPOP/SMOVE/SCARD
- SINTER/SDIFF/SDIFFSTORE/SUNION
Set类型主要应用于:在某些场景,如社交场景中,通过交集、并集和差集运算,通过Set类型可以非常方便地查找共同好友、共同关注和共同偏好等社交关系。
1.4.5、顺序集合类型(sorted set)
ZSet是一种有序集合类型,每个元素都会关联一个double类型的分数权值,通过这个权值来为集合中的成员进行从小到大的排序。与Set类型一样,其底层也是通过哈希表实现的。
ZSet命令:
- ZADD/ZPOP/ZMOVE/ZCARD/ZCOUNT
- ZINTER/ZDIFF/ZDIFFSTORE/ZUNION
1.5、Redis的数据结构
Redis的数据结构如下图所示: 
关于上表中的部分释义:
- 1、压缩列表是列表键和哈希键的底层实现之一。当一个列表键只包含少量列表项,并且每个列表项要么就是小整数,要么就是长度比较短的字符串,Redis就会使用压缩列表来做列表键的底层实现
- 2、整数集合是集合键的底层实现之一,当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis就会使用整数集合作为集合键的底层实现
1.6、Redis常见问题解析
1.6.1、击穿
概念:在Redis获取某一key时, 由于key不存在, 而必须向DB发起一次请求的行为, 称为“Redis击穿”。 
引发击穿的原因:
- 第一次访问
- 恶意访问不存在的key
- Key过期
合理的规避方案:
- 服务器启动时, 提前写入
- 规范key的命名, 通过中间件拦截
- 对某些高频访问的Key,设置合理的TTL或永不过期
1.6.2、雪崩
概念:Redis缓存层由于某种原因宕机后,所有的请求会涌向存储层,短时间内的高并发请求可能会导致存储层挂机,称之为“Redis雪崩”。
合理的规避方案:
- 使用Redis集群
- 限流
2、redis进阶
2.1、Redis协议简介
Redis客户端通讯协议:RESP(Redis Serialization Protocol),其特点是:
- 简单
- 解析速度快
- 可读性好
Redis集群内部通讯协议:RECP(Redis Cluster Protocol ) ,其特点是:
- 每一个node两个tcp 连接
- 一个负责client-server通讯(P: 6379)
- 一个负责node之间通讯(P: 10000 + 6379)
3、其他NoSQL型数据库
市面上类似于Redis,同样是NoSQL型的数据库有很多,如下图所示,除了Redis,还有MemCache、Cassadra和Mongo。下面,我们就分别对这几个数据库做一下简要的介绍: 
- Memcache:
- 这是一个和Redis非常相似的数据库,但是它的数据类型没有Redis丰富。Memcache由LiveJournal的Brad Fitzpatrick开发,作为一套分布式的高速缓存系统,被许多网站使用以提升网站的访问速度,对于一些大型的、需要频繁访问数据库的网站访问速度的提升效果十分显著。
- Apache Cassandra:
- (社区内一般简称为C*)这是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存收件箱等简单格式数据,集Google BigTable的数据模型与Amazon Dynamo的完全分布式架构于一身。Facebook于2008将 Cassandra 开源,由于其良好的可扩展性和性能,被 Apple、Comcast、Instagram、Spotify、eBay、Rackspace、Netflix等知名网站所采用,成为了一种流行的分布式结构化数据存储方案。
- MongoDB:
- 是一个基于分布式文件存储、面向文档的NoSQL数据库,由C++编写,旨在为WEB应用提供可扩展的高性能数据存储解决方案。MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系型数据库的,它支持的数据结构非常松散,是一种类似json的BSON格式。
4、终端中使用redis
4.1、连接redis服务
redis默认端口为 6379
无密码连接运行
sh
[root@VM-0-2-centos ~]# redis-cli
或者
[root@VM-0-2-centos ~]# redis-cli -h 127.0.0.1 -p 6379有密码连接运行
sh
redis-cli -h 127.0.0.1 -p 6379 -a "password"5、redis常用操做
5.1、写入数据
sh
set <key> <value>
例如:set age 12 # 写入age的为12
5.2、读取数据
sh
get <key>
例如:get age # 读取age的值---> 输出12
5.3、查询所有的key
sh
keys * # 输出所有的key
5.4、中文乱码问题
输入和显示中文时,默认会显示乱码,这时启动时在后面加 --raw ,输入时会乱码,但是显示时就能正常显示了
sh
redis-cli -h 127.0.0.1 -p 6379 -a "password" --raw

5.5、获取所有的键的数量
sh
dbsize # 输出键的数量
5.6、检查键是否存在
sh
exists <key> # 输出1表示存在,输出0表示不存在
5.7、删除键(单个,多个)
sh
del <key1> <key2> ...

5.8、查看键的类型(键的数据结构类型)
sh
type <key>
5.9、重命名键
仅当 newkey 不存在时,将 key 改名为 newkey
sh
rename <key> <新名字>
5.10、过期时间
设置key的过期时间,超过时间后,将会自动删除该key. 参考:https://www.cnblogs.com/sunshine-long/p/12706868.html
(1)设置一个key在当前时间"seconds"(秒)之后过期 expire
EXPIRE <key> <秒> # 返回1表示设置成功,返回0代表key不存在或者无法设置过期时间。

(2)设置一个key在当前时间"milliseconds"(毫秒)之后过期 pexpire
PEXPIRE <key> <毫秒> # 返回1表示设置成功,返回0代表key不存在或者无法设置过期时间。 1秒===1000毫秒 
(3)设置一个key在"timestamp"(时间戳(秒))之后过期 expireat
EXPIREAT <key> <时间戳(秒)> #返回1代表设置成功,返回0代表key不存在或者无法设置过期时间。 
(4)设置一个key在"milliseconds-timestamp"(时间戳(毫秒))之后过期 pexpireat
PEXPIREAT <key> <时间戳(毫秒)> # 返回1代表设置成功,返回0代表key不存在或者无法设置过期时间 
(5)获取key的过期时间(秒) TTL <key>
TTL <key>
- 如果key存在过期时间,返回剩余生存时间(秒);
- 如果key是永久的,返回-1;
- 如果key不存在或者已过期,返回-2。
(6)获取key的过期时间(毫秒)
PTTL <key>
- 如果key存在过期时间,返回剩余生存时间(毫秒);
- 如果key是永久的,返回-1;
- 如果key不存在或者已过期,返回-2。
(7)移除key的过期时间,将其转换为永久状态
PERSIST <key>
- 如果返回1,代表转换成功。
- 如果返回0,代表key不存在或者之前就已经是永久状态。
(8)写入数据,同时设置过期时间(几秒)
SETEX <key> 秒 <value>
- SETEX在逻辑上等价于SET和EXPIRE合并的操作,区别之处在于SETEX是一条命令,而命令的执行是原子性的,所以不会出现并发问题。
(9)redis如何清理过期key?
redis出于性能上的考虑,无法做到对每一个过期的key进行即时的过期监听和删除。但是redis提供了其它的方法来清理过期的key。
9.1)被动清理
- 当用户主动访问一个过期的key时,redis会将其直接从内存中删除
9.2)主动清理
- 在redis的持久化中,我们知道redis为了保持系统的稳定性,健壮性,会周期性的执行一个函数。在这个过程中,会进行之前已经提到过的自动的持久化操作,同时也会进行内存的主动清理。
- 在内存主动清理的过程中,redis采用了一个随机算法来进行这个过程:简单来说,redis会随机的抽取N(默认100)个被设置了过期时间的key,检查这其中已经过期的key,将其清除。同时,如果这其中已经过期的key超过了一定的百分比M(默认是25),则将继续执行一次主动清理,直至过期key的百分比在概率上降低到M以下。
9.3)内存不足时触发主动清理
- 在redis的内存不足时,也会触发主动清理
6、redis中一些热门问题
6.1、redis内存不足时的策略
redis是一个基于内存的数据库,如果存储的数据量很大,达到了内存限制的最大值,将会出现内存不足的问题。redis允许用户通过配置maxmemory-policy参数,指定redis在内存不足时的解决策略
centos默认的redis配置文件在/etc/redis.conf 可以通过whereis redis 命令查看配置文件在哪

1、volatile-lru 使用LRU算法删除一个键(只针对设置了过期时间的key 2、allkeys-lru 使用LRU算法删除一个键 3、volatile-lfu 使用LFU算法删除一个键(只针对设置了过期时间的键) 4、allkeys-lfu 使用LFU算法删除一个键 5、volatile-random 随机删除一个键(只针对设置了过期时间的键) 6、allkeys-random 随机删除一个键 7、volatile-ttl 删除最早过期的一个键 8、noeviction 不删除键,返回错误信息(redis默认选项)
对于只针对设置了过期时间的键进行删除的策略,在所有的可被删除的键(非永久的键)都被删除时内存依然不足,将会抛出错误。 其中,LRU算法--->最近最少使用算法,较为注重于时间;LFU算法--->最近最不常用算法,较为注重于被访问频率。
redis的内存置换算法和操作系统中的内存置换算法类似。
6.2、redis中数据持久化怎么实现?
为什么要持久化?
- 由于Redis的数据都存放在内存中,如果没有配置持久化,redis重启后数据就全丢失了,于是需要开启redis的持久化功能,将数据保存到磁盘上,当redis重启后,可以从磁盘中恢复数据
redis提供两种方式进行持久化,
- RDB持久化(原理是将Reids在内存中的数据库记录定时dump到磁盘上的RDB持久化)
- AO持久化(原理是将Reids的操作日志以追加的方式写入文件)
6.2.1 RDB持久化
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
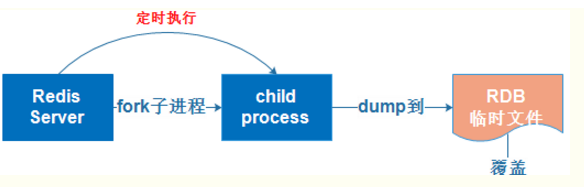
特点:
- 基于快照的持久化,速度更快,一般用作备份,主从复制也是依赖于rdb持久化功能
实现ROB持久化
1)修改配置文件redis.conf(修改前先备份)
centos默认位置/etc/redis.conf
sh
daemonize yes
port 6379
logfile /data/6379/redis.log
dir /data/6379 #定义持久化文件存储位置
dbfilename dbmp.rdb #rdb持久化文件
bind 10.0.0.10 127.0.0.1 #redis绑定地址
requirepass 123 #redis登录密码
save 900 1 #rdb机制 每900秒 有1个修改记录
save 300 10 #每300秒 10个修改记录
save 60 10000 #每60秒内 10000修改记录2)通过save触发持久化,将数据写入RDB文件

之后,可以在持久化目录下查看.rdb持久化文件 
6.2.2 AOF持久化(append only file)
AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
 特点:
特点:
- 以追加的方式记录redis操作日志的文件。可以最大程度的保证redis数据安全,类似于mysql的binlog
- 优点:最大程度保证数据不丢
- 缺点:日志记录非常大
实现AOF持久化
1)修改配置文件 redis.conf(先备份)
centos默认位置/etc/redis.conf
## AOF持久化配置,两条参数
appendonly yes
appendfsync always # 总是修改类的操作
everysec # 每秒做一次持久化
no # 依赖于系统自带的缓存大小机制2)写入数据,检查redis数据目录/data/6379/是否产生了aof文件,关闭redis,检查数据是否持久化
6.3、redis 主从同步(Master&Slave)?
6.3.1 是什么?
- 主从复制:主机数据更新后根据配置和策略,自动同步到备机的master/slave机制,Master以写为主,Slave以读为主

6.3.2 能干啥?
- 读写分离 容灾备份
6.3.3 主从复制原理?
- 1、从服务器向主服务器发送 SYNC 命令。
- 2、接到 SYNC 命令的主服务器会调用BGSAVE 命令,创建一个 RDB 文件,并使用缓冲区记录接下来执行的所有写命令。
- 3、当主服务器执行完 BGSAVE 命令时,它会向从服务器发送 RDB 文件,而从服务器则会接收并载入这个文件。
- 4、主服务器将缓冲区储存的所有写命令发送给从服务器执行。
6.3.4 怎么实现?
https://www.cnblogs.com/peng104/p/10274857.html#autoid-1-3-0
6.4、怎么在Node项目中怎么使用redis?
6.4.1 egg-redis
在egg项目中,egg提供了egg-redis插件,也有很好的文档,地址如下 github地址:https://github.com/eggjs/egg-redis
默认使用的get和set方法操作的字符串类型 如果想操作其他类型:取巧可以直接用字符串表示,JSON.stringify,JSON.parse
6.4.2 使用ioredis
适用于Node.js 的强大、注重性能且功能齐全的Redis客户端。 支持 Redis >= 2.6.12 和 (Node.js >= 6)。完全兼容Redis 6.x。
github地址:https://github.com/luin/ioredis
egg-redis 就是在 ioredis 上包了一层,所以 ioredis 的 api 和 egg-redis 是通用的 ioredis 是官方推荐的 nodejs 客户端,建议不要直接用 redis 模块
使用egg-redis时不知道非字符串类型的操作方法时,直接查看ioredis的api即可
6.4.3 redis+mysql的使用
首先redis在key value值查询的速度高于mysql,所以缓存有利于提高性能;
redis是内存型数据库,不可能存储过大的数据;
mysql是存储在硬盘上的,可以支持更大规模的数据,成本更低
一般mysql结合redis缓存,
读取数据时先从redis中查询,查询不到再从mysql中查询; 写入数据首先更新mysql,然后拿到更新结果之后,刷新缓存数据或者删除缓存数据 具体可以看下一节(6.5、如何保持mysql和redis中数据的一致性?)
6.5、如何保持mysql和redis中数据的一致性?
现在很多架构都采用了Redis+MySQL来进行存储,但是由于多方面的原因,总会导致Redis和MySQL之间出现数据的不一致性。
例如:
- 如果一个事务执行失败回滚了,但是如果采取了先写Redis的方式,就会造成Redis和MySQL数据库的不一致,
再比如说,
- 一个事务写入了MySQL,但是此时还未写入Redis,如果这时候有用户访问Redis,则此时就会出现数据不一致。
为了解决这些问题,以下提供集中解决方案:
1)分别处理
针对某些对数据一致性要求不是特别高的情况下,可以将这些数据放入Redis,请求来了直接查询Redis,例如近期回复、历史排名这种实时性不强的业务。而针对那些强实时性的业务,例如虚拟货币、物品购买件数等等,则直接穿透Redis至MySQL上,等到MySQL上写入成功,再同步更新到Redis上去。这样既可以起到Redis的分流大量查询请求的作用,又保证了关键数据的一致性。
2)高并发情况下
此时如果写入请求较多,则直接写入Redis中去,然后间隔一段时间,批量将所有的写入请求,刷新到MySQL中去;如果此时写入请求不多,则可以在每次写入Redis,都立刻将该命令同步至MySQL中去。这两种方法有利有弊,需要根据不同的场景来权衡。
3)基于订阅binlog的同步机制
阿里巴巴的一款开源框架canal,提供了一种发布/ 订阅模式的同步机制,通过该框架我们可以对MySQL的binlog进行订阅,这样一旦MySQL中产生了新的写入、更新、删除等操作,就可以把binlog相关的消息推送至Redis,Redis再根据binlog中的记录,对Redis进行更新。值得注意的是,binlog需要手动打开,并且不会记录关于MySQL查询的命令和操作。
其实这种机制,很类似MySQL的主从备份机制,因为MySQL的主备也是通过binlog来实现的数据一致性。而canal正是模仿了slave数据库的备份请求,使得Redis的数据更新达到了相同的效果。如下图就可以看到Slave数据库中启动了2个线程,一个是MySQL SQL线程,这个线程跟Matser数据库中起的线程是一样的,负责MySQL的业务率执行,而另外一个线程就是MySQL的I/O线程,这个线程的主要作用就是同步Master 数据库中的binlog,达到数据备份的效果。而binlog就可以理解为一堆SQL语言组成的日志。