
主题
文件分片上传(前端部分)
分片上传就是将单个文件作切分为多个小块(chunk),每个 chunk 都是文件数据的连续部分。然后按任意顺序独立上传这些分片。如果任意分片传输失败,可以重新传输该分片且不会影响其他分段。上传完所有的对象分段后,服务器将汇集这些分段并合并为一个完整文件。
使用时机
一般而言,如果您的对象大小达到了 100 MB,就应该考虑使用分片上传,而不是使用常规的单文件上传。
分片上传的优势
- 提高吞吐量(上传效率) – 您可以并行上传分段以提高吞吐量,加快上传进度。
- 从任何网络问题中快速恢复 – 较小的分段大小可以将由于网络错误而需重启失败的上传所产生的影响降至最低。
- 暂停和恢复对象上传 – 您可以在一段时间内逐步上传对象分段。启动分段上传后,不存在过期期限;您必须显式地完成或停止分段上传。
分片上传的大致步骤
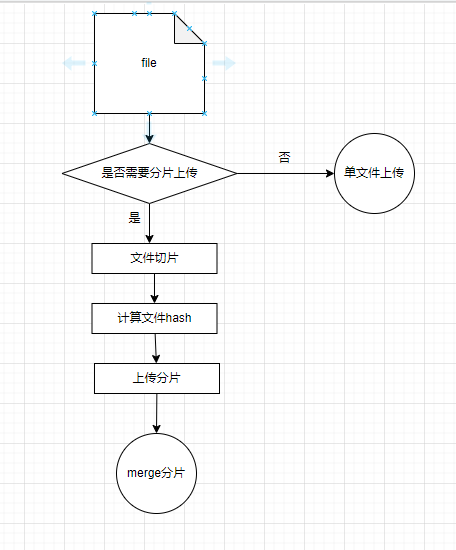
- 是否需要分片上传:这一步一般会根据文件大小做判断,只有文件大小满足一定的阈值才需要使用呢分片上传策略,文件太小就没有意义了
- 文件切片:浏览器环境中,File 对象继承自 Blob 对象,Blob 有一个
Blob.slice()方法,返回一个新的 Blob 对象,其中包含调用它的 blob 的指定字节范围内的数据。 - 计算文件 hash 值的作用主要是用于向服务器询询问当前文件是否有已上传的部分,用于后续实现文件秒传功能,可以使用第三方包
spark-md5 - 上传分片:不讲究分片的上传顺序,可以使用并发上传
- merge 分片:这一步是服务器的工作,但是需要前端在所有分片都上传完成后告诉服务器可以进行分片合并
下面就针对上面步骤来一一实现前端文件上传功能
(1)是否需要分片上传
这一步很简单,首先需要获取用户上传的文件,然后判断文件大小,来决定采用分片上传还是单文件上传
获取上传的文件
html
<input type="file" onchange="chooseFile" />
<script>
function chooseFile(e) {
const file = e.target.files[0]; // 上传的文件
}
</script>接着是判断文件的大小,与之对比的是一个阈值,根据实际业务场景定一个就好,我这里随便定义了一个,例如为 10M
js
// (字节单位) 超过10M的文件需要分片
const SIZE_LIMIT = 10 * 1024 * 1024;提示
file.size 的单位为字节
1TB = 1024GB
1GB = 1024MB
1MB = 1024KB
1KB= 1024 bit(字节)
于是
js
if (file.size <= SIZE_LIMIT) {
// 采用单文件上传的方式
// 直接调单文件上传接口
} else {
// 采用分片上传
}(2)文件切片
文件切片需要明确每个分片的大小,分片不要太大,也不要太小,需要根据具体的业务场景来分析
若分片太大,会影响上传的速度,若分片太小,一个大文件需要发起很多的分片上传请求,也会对效率有一定影响
若对接的是一些云对象存储或者文件服务,他们一般都会支持分片上传文件,需要查一下对应服务的限制
AWS S3 有分片数量和分片大小的限制
- 不分片上传:单个文件最大 5GB
- 分片上传:每个片的大小在 5MB 到 5GB 之间,最后一个分片大小可以小于 5MB,可以有 10000 个分片数量,所以最大单个文件可以达到 5TB.
我这里定一个分片大小为 8MB
js
// (字节单位) 分片大小8M
const CHUNK_SIZE = 8 * 1024 * 1024;文件切片很简单,只需要根据分片大小对文件进行切割即可
js
// 文件分片
function splitFile(file) {
// 文件需要分成多少片(分片数量)
const chunkCount = Math.ceil(file.size / CHUNK_SIZE);
const chunkInfos = []; // 所有分片信息
for (let index = 0; index < chunkCount; index++) {
const start = index * CHUNK_SIZE;
const end = Math.min((index + 1) * CHUNK_SIZE, file.size); // 最后一片分片可能不足8MB
chunkInfos.push({
blob: file.slice(start, end, file.type),
partNumber: index + 1, // 当前分片的排序,用于merge分片,S3 partNumber从1开始
contentType: file.type,
fileName: file.name,
});
}
return chunkInfos;
}(3)计算文件 hash
计算文件 hash 用的是spark-md5,使用很简单:
js
import SparkMd5 from "spark-md5";
const spark = new SparkMd5();
const reader = new FileReader();
reader.onload = function (e) {
const content = e.target.result;
spark.append(content);
const fileHash = spark.end(); // 文件hash
};
reader.readAsArrayBuffer(file);但是,读取一个很大文件,代码一运行,发现很慢很慢......
分析: 上述代码分为读取文件内容 和 计算文件 hash 两个步骤 读取文件内容的操作其实很快,但是计算文件的 contenthash 的操作需要经过大量计算,会很耗费性能,而且读取文件会将整个文件读取后放入内存中,若是读取的文件很大,有几个 GB,那这个操作简直要逆天,没法用
我们可以将分片后,一块一块的读取,采用增量计算的方式来计算文件 hash,读取一块计算,计算一块,计算完就丢弃,这样既可以保证效率也不至于太消耗性能,而且读文件属 I/O 操作,是异步的,需要使用 promise 来提高代码可读性
于是
js
// 计算文件hash值
async function calcFileHash(source) {
try {
const spark = new SparkMD5.ArrayBuffer();
if (Array.isArray(source)) {
for (let index = 0; index < source.length; index++) {
const chunkInfo = source[index];
const content = await readFile(chunkInfo.blob);
spark.append(content);
}
} else {
const content = await readFile(source);
spark.append(content);
}
return spark.end();
} catch (error) {
throw error;
}
}
// 读取文件为arrayBuffer
function readFile(chunk) {
return new Promise((resolve, reject) => {
const reader = new FileReader();
reader.onload = (e) => {
resolve(e.target.result);
};
reader.onerror = reject;
reader.readAsArrayBuffer(chunk);
});
}(4)上传分片
上传分片就是调上传分片的接口,将分片上传到服务器,没有什么复杂操作
但是需要注意的点是:并行,并行,并行,重要的事情说三遍,别还傻傻的采用串行。
采用并行并不是直接 Promise.all 就行了,否则你会发现有一些请求会无缘无故的失败,因为浏览器的并发请求数量是有限的,chrome 默认为 6,也就是说即使你同时发起 100 个请求,并不会将 100 个请求同时发出去,而是只有 6 个请求处于发送状态,其余请求都处于 padding 状态,若网络慢点,靠后的请求可能会因为 timeout 而失败,因此控制并发量很有必要,这里我原来写了一个控制并发的插件,async-pool
(5)文件秒传
文件秒传,指的是上传一个文件,速度飞快,一下子就上传好了,原理就是在上传文件之前,询问一下这个文件是否已经上传过,需要服务器的支持,若上传过,则服务器会直接告诉我们文件地址,也就免去了再上传一次的步骤,在前端界面看上去就是一下子就上传好了
整个文件:前端要做的就是用上面(3)中计算好的文件 hash,发请求询问服务器,这个文件是否上传过,因为上面计算的 hash 为 contentHash,可以代表文件的唯一标识,无论文件位置是否一致,contentHash 都使用文件内容计算出来的,只要文件内容有一点改变,hash 都不一样
分片:在(4)分片上传之前,也需要询问一下服务器,当前这个文件,已经上传了哪些分片了,前端就知道还剩余哪些分片未上传,只需要上传这部分分片就好
(6)上传进度
上传进度就很简单了,我们已经知道当前文件 slice 出的分片数量chunkTotal,那么 上传进度 = 已上传的分片数量 / chunkTotal * 100 就是当前上传进度的百分比
- 单文件上传进度
js
axios({
url: "http://localhost:8080/chunk",
method: "POST",
data,
onUploadProgress: (e) => {
let progress = (e.loaded / e.total) * 100; // 进度
},
});
// API封装一下
const singleFileUpload = (data, onUploadProgress) =>
axios({ url: ".....", method: "POST", data, onUploadProgress });
// 在页面内使用
// ....
singleFileUpload(data, (progressEvent) => {
let progress = (e.loaded / e.total) * 100; // 进度
});
// ....(7)取消上传、暂停
这俩都需要取消当前正在上传的接口的请
- 原理:
- 发出取消或者暂停指令后,终止还未上传的 chunk 的请求
- 发出恢复上传指令后,继续那些还未上传的 chunk 的上传操作
注意版本:v0.22.0 前后操作方式有所区别
- V0.22.0以前示例:
js
import axios from "axios";
const CancelToken = axios.CancelToken;
let cancel;
axios.get("/user/12345", {
cancelToken: new CancelToken(function executor(c) {
// executor 函数接收一个 cancel 函数作为参数
cancel = c;
}),
});
// 取消请求
cancel();
// 或者
const CancelToken = axios.CancelToken;
const source = CancelToken.source();
axios.get('/user/12345', {
cancelToken: source.token
}).catch(function (thrown) {
if (axios.isCancel(thrown)) {
console.log('Request canceled', thrown.message);
} else {
// 处理错误
}
});
axios.post('/user/12345', {
name: 'new name'
}, {
cancelToken: source.token
})
// 取消请求(message 参数是可选的)
source.cancel('Operation canceled by the user.');- V0.22.0开始
js
const controller = new AbortController();
axios.get('/foo/bar', {
signal: controller.signal
}).then(function(response) {
//...
});
// 取消请求
controller.abort()如何取消上传分片的请求?
在 uploadParts 的过程中,可以给每一个 chunkItem 身上挂一个取下函数,并且加一个标识,当前 chuank 是否已经上传成功
- 请求示例:
js
import axios from "axios";
import { asyncPool } from "@mrli-utils/asyncpool";
const CancelToken = axios.CancelToken;
const source = CancelToken.source();
// 每一个chunk身上都有这些属性
const chunkItem = {
blob: chunk,
partNumber: index + 1, // 当前分片的排序,用于merge分片,S3 partNumber从1开始
contentType: file.type,
fileName: file.name,
};
// 组装chunk上传的参数
const uploadRequestParams = noUploadedParts.map((chunkItem) => {
const data = new FormData();
data.append("chunk", chunkItem.blob);
return [chunkItem, data];
});
// uploadPart请求的函数切片
async function uploadPartHandler(chunkItem, data) {
try {
const res = await uploadPar(data, source.tokan);
chunkItem.status = 1; // 1-表示上传成功状态
} catch (e) {
throw e;
}
}
// 并发控制上传分片 uploadPart为真实的上传分片接口,接手3个参数, chunkItem, data 和 cancelToken
asyncPool(6, uploadRequestParams, uploadPartHandler).then((res) => {
console.log(res);
});- 取消请求示例:
js
// 取消请求(message 参数是可选的)
source.cancel('Operation canceled by the user.');(8)合并分片
合并分片对于前端就很简单了,只需要调用合并接口,告诉服务器有多少分片,顺序是什么,由服务器合并成功后返回一个文件地址, 文件分片上传就结束了
优化点
- 计算 hash 可以用多线程(Web Worder),避免阻塞主线程